Kompilator to nic strasznego, czyli jak działa Twój kod pod spodem?


- Czas potrzebny na przeczytanie:3 minuty
- Opublikowane:



Załóżmy, że pracujesz nad nową aplikacją w JavaScripcie, czytasz wymagania biznesowe, wszystko jest jasne i klarowne... Aż do ostatniego podpunktu wymagań - kompatybilność z Internet Explorer 😬 Zanim rzucisz wypowiedzeniem na stół swojego szefa wykrzykując, że nie będziesz pisał w prehistorycznym standardzie ES3, przeczytaj ten artykuł, bo jest sposób na zachowanie pracy i zdrowia psychicznego w tym projekcie!
Jak działają kompilatory?
Piszesz nowy, zajebisty kodzik w JS, a wysyłasz do przeglądarki kod "legacy", taki, żeby był kompatybilny ze środowiskiem uruchomieniownym, w naszym przypadku z przeglądarką IE starszej generacji. Ten opis idealnie pasuje do najpopularniejszego kompilatora w naszym JS'owym środowisku - Babela. Babel nie jest wyjątkiem w naszej branży jeśli chodzi o kompilatory. Innym przykładem może być również kompilator TSa, który kompiluje kod z tego języka na pełnoprawny JavaScript.
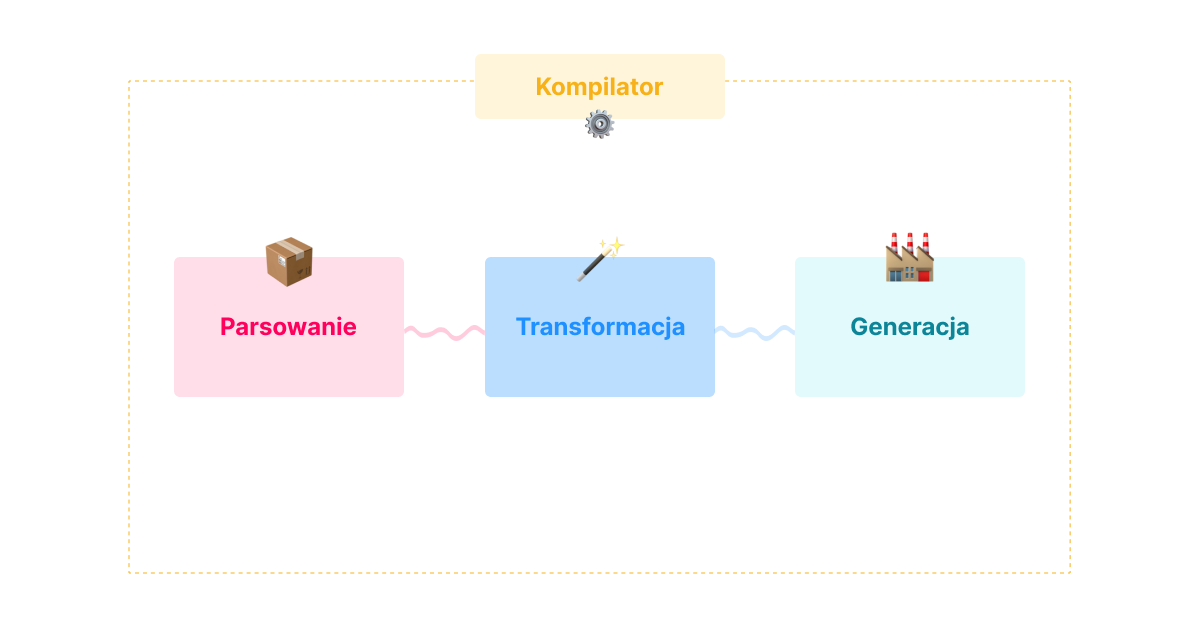
Wiemy już czym są i jakie problemy rozwiązują, ale jak tak naprawdę działają kompilatory? Proces kompilacji możemy podzielić na trzy etapy:
- Parsowanie - kompilator bierze surowy kod i przekształca go w jego abstrakcyjną reprezentację
- Transformacja - kompilator korzysta z przetworzonej, abstrakcyjnej reprezentacji kodu i modyfikuje ją według potrzeb
- Generacja - przetransformowana, abstrakcyjna reprezentacja kodu zostaje z powrotem wygenerowana w zwykły kod
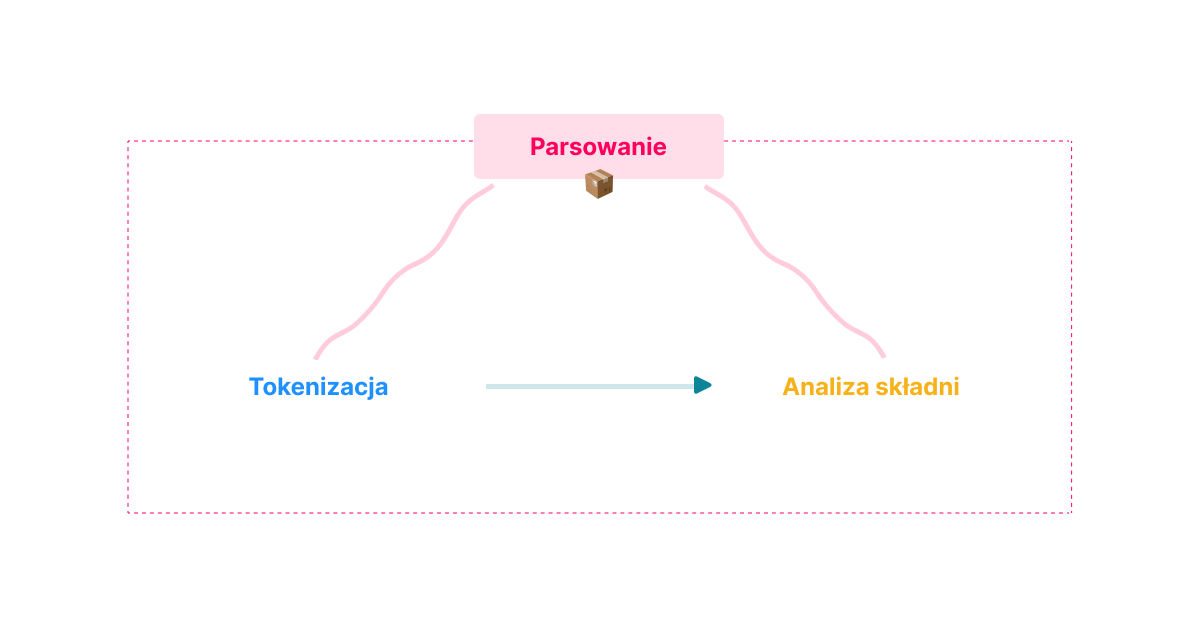
Parsowanie
Pierwszy z procesów, proces parsowania. To w nim Twój kod będzie czytany przez kompilator. Po przemieleniu, jeśli wszystko poszło okej, kod zostanie sprasowany do tzw. Abstract Syntax Tree (AST), czyli drzewiastej reprezentacji kodu, do której za chwilę przejdziemy.
W procesie parsowania rozróżniamy jeszcze dwa podprocesy:
- Tokenizację
- Analizę składni
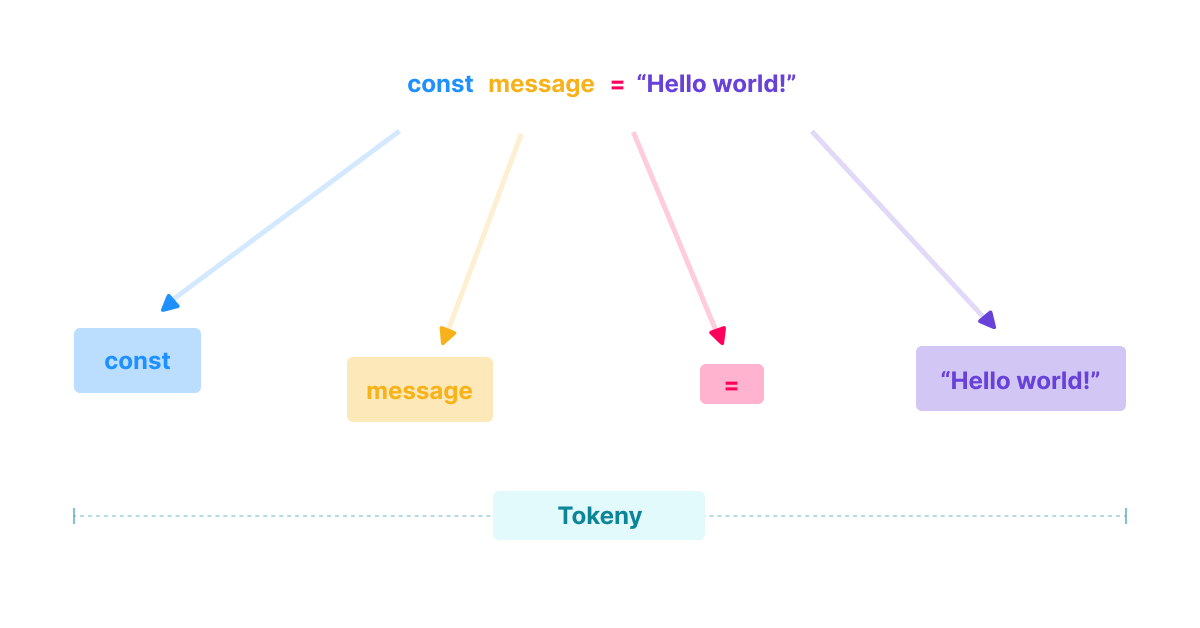
Tokenizacja
Tokenizacja, zwana również analizą leksykalną (ang. lexical analysis) to proces przekształcania ciągu znaków w odpowiednio oznaczone tokeny.
Weźmy taki kawałek kodu const message = "Hello world!", po przemieleniu go przez tokenizer otrzymamy cztery tokeny - const, message, = oraz "Hello world!".
Analiza składni
Tak odseparowane kawałki kodu są wysyłane do tzw. analizy składni (ang. syntax/syntactic analysis). Kompilator przechodzi przez każdy token i tworzy z nich wcześniej wspomnianą abstrakcyjną reprezentację kodu, czyli Abstract Syntax Tree (AST):
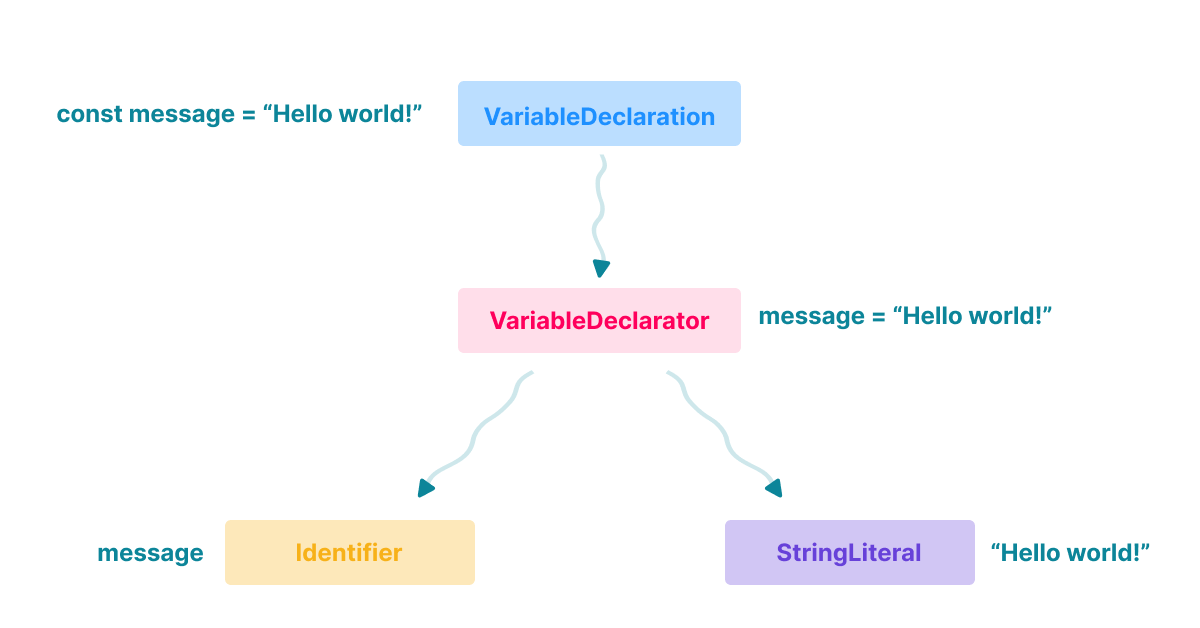
Dla naszego skrawka kodu AST może wyglądać w taki sposób (uproszczone, format: JSON):
{
"type": "Program",
"start": 0,
"end": 33,
"sourceType": "module",
"interpreter": null,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 31,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 30,
"id": {
"type": "Identifier",
"start": 6,
"end": 13,
"name": "message"
},
"init": {
"type": "StringLiteral",
"start": 16,
"end": 30,
"value": "Hello world!"
}
}
],
"kind": "const"
}
]
}
Newsletter dla Frontend Developerów 📮


Transformacja
W tym etapie dostajemy wcześniej przygotowany AST i możemy z nim robić co tylko chcemy! Jak mogłeś zauważyć, drzewo zbudowane jest z podobnych do siebie obiektów zwanymi AST nodes:
Node dla VariableDeclaration:
{
"type": "VariableDeclaration",
"start": 0,
"end": 31,
"declarations": [...],
}
Każdego takiego nołda możemy modyfikować w dowolny sposób.
Spróbujmy stworzyć mechanizm, który zamieni nasz współczesny kod, w polską rezprezentację kodu sprzed ery ES6, coś na wzór słynnego isPies :) Żeby odpowiednio zmodyfikować nołdy, będziemy potrzebować obiektu visitor, w którym nazwy metod będą odpowiadały typom z AST:
{
visitor: {
VariableDeclaration(path) {
path.node.kind = "var";
},
Identifier(path) {
path.node.name = "wiadomość";
},
StringLiteral(path) {
path.node.value = "Witaj świecie!";
}
}
}
Chcesz wypróbować ten mechanizm transformacji? Sprawdź AST Explorer ⚙️
Generacja
Ostatni z procesów, bierzemy przetransformowane drzewo AST i z powrotem zmieniamy jest w ciąg znaków. Kompilator będzie przechodził przez wszystkie AST nodes dopóki const message = "Hello world!" nie zamieni się w piękne var wiadomość = "Witaj świecie!".
Podsumowanie
To by było na tyle jeśli chodzi o kompilatory ⚙️ Bez zbędnego gadania, pomijając szczegóły technicznie, tak żeby uprościć temat jak tylko się da. Jeśli chcesz się trochę bardziej wgłębić w samą implementację, to polecam Ci pierwszy z linków w źródłach, autor tworzy w nim maleńki kompilator w JavaScript 🔥



